

Can A Json Script Extract Data From Pdf
How to Excerpt Data from PDF Forms Using Python
Understanding the Object Model of PDF Documents for Information Mining
Introduction
PDF or Portable Document File format is one of the nigh common file formats in employ today. It is widely used beyond enterprises, in authorities offices, healthcare and other industries. As a consequence, at that place is a big body of unstructured data that exists in PDF format and to extract and analyse this data to generate meaningful insights is a common task amongst information scientists.
I work for a financial institution and recently came across a situation where we had to excerpt data from a large volume of PDF forms. While there is a good body of work available to describe simple text extraction from PDF documents, I struggled to find a comprehensive guide to extract data from PDF forms. My objective to write this commodity is to develop such a guide.
There are several Python libraries dedicated to working with PDF documents, some more than pop than the others. I will exist using PyPDF2 for the purpose of this article. PyPDF2 is a Pure-Python library built as a PDF toolkit. Being Pure-Python, it can run on any Python platform without whatever dependencies or external libraries. You can use pip to install this library by executing the code beneath.
pip install PyPDF2 Once you have installed PyPDF2, you lot should exist all set to follow along. We will accept a quick expect at the construction of PDF files equally information technology will assist us to better sympathise the programmatic footing of extracting information from PDF forms. I will briefly discuss the 2 types of PDF forms that are widely used. Nosotros will then jump correct into the examples to extract information from each of the ii types of PDF forms.
Construction of a PDF file
Instead of looking at PDF document as a monolith, information technology should be looked at as a collection of objects. All of these objects are bundled in a set pattern. If y'all open a PDF file in a text editor such as notepad, the content may not make much sense and appear to be junk. However, if you lot employ a tool that provides depression level access to PDF objects, you could see and appreciate the underlying construction. For example, delight look at Figure 1 beneath. I used iText RUPS to open a unproblematic PDF document.The image on the left is of a simple PDF document I opened in a reader application(Acrobat Reader). The centre image displays the low level object model of this document as rendered by iText RUPS. The image on the Right shows the information stream that captures the content of the PDF on its beginning folio. Every bit yous could see, the object model(centre image) has a prepare blueprint and encapsulates all of the meta data that is needed to render the document independent of the software, hardware, operating system etc. This structure is what makes PDF so versatile and popular.

PDF Forms
At that place are 2 primary types of PDF forms.
- XFA (XML Forms Architecture) based Forms
- Acroforms
Adobe(the company that adult PDF format) has an application called AEM (Adobe Feel Manager) Forms Designer, which is aimed at enabling customers to create and publish PDF forms. Adobe uses the term PDF form to refer to the interactive and dynamic forms created with AEM Forms Designer. These PDF forms are based on Adobe's XML Forms Compages (XFA), which is based on XML. These forms can be dynamic in nature and can reflow PDF content based on user input.
There'south some other type of PDF form, called an Acroform. Acroform is Adobe'due south older and original interactive form technology introduced in 1996 as a part of PDF 1.2 specification. Acroforms are a combination of a traditional PDF that defines the static layout with Interactive grade fields that are bolted on acme. First, you pattern the form layout using Microsoft Word, Adobe InDesign, or Adobe Illustrator, etc. Then yous add the form elements — fields, dropdown controls, checkboxes, script logic etc.
Extracting Information from XFA Based PDF Forms
Figure 2 beneath shows a screenshot of the XFA based PDF form that we will be using every bit an example for this practice. This is a Currency Transactions Report form used by the banks and other institutions to report certain financial transactions to the regulatory bureau. This is a dynamic grade where you could add and remove sections based on the amount of information that needs to exist reported. I take partially filled this form with some dummy data.
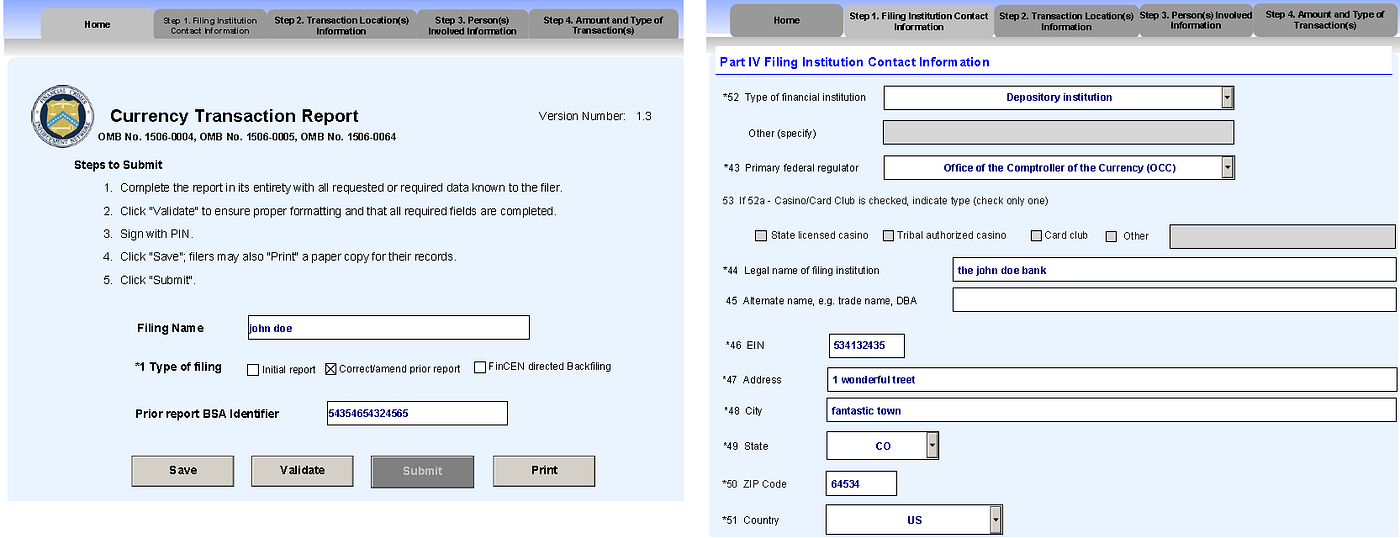
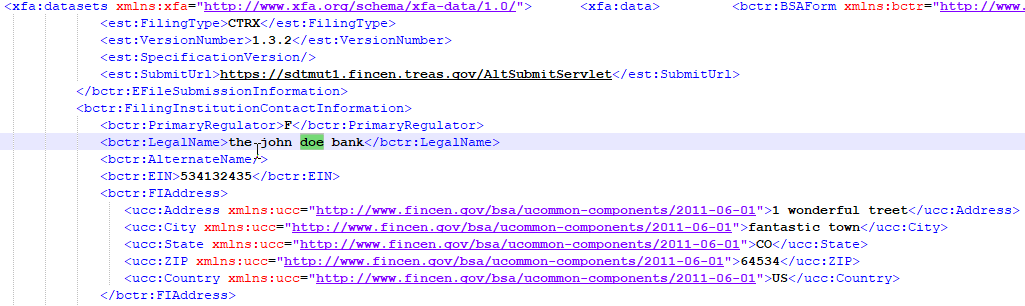
Figure three shows the object model of this course. The XML document, shown on the correct side of the image is what makes upwardly the XFA, which is stored as the value of the XFA key inside the AcroForm dictionary(await at the object model on the left side of the image). The Acroform dictionary is a kid chemical element of the Catalog dictionary, which in turn is housed inside the Root of this PDF file. All we demand to do is use PyPDF2 to access the XML document from the object construction of this file. One time we accept access to the XML, it is a simple exercise of parsing out the XML certificate to access values for various form elements, which could then be stored into a Python list, Numpy array, Pandas dataframe etc. for the purpose of analysis.

Below is the code to extract the XML that makes upwards this form.
import PyPDF2 as pypdf def findInDict(needle, haystack):
for key in haystack.keys():
try:
value=haystack[key]
except:
continue
if key==needle:
return value
if isinstance(value,dict):
x=findInDict(needle,value)
if x is not None:
return x pdfobject=open('CTRX_filled.pdf','rb') pdf=pypdf.PdfFileReader(pdfobject) xfa=findInDict('/XFA',pdf.resolvedObjects)
xml=xfa[vii].getObject().getData()
In the first line, I am simply importing the PyPDF2 library and providing it an alias — pypdf. The 2d line is the beginning of function definition to find elements of a lexicon by providing the lexicon cardinal. You would recall from our discussion above, that our XML is embedded inside a dictionary referenced by the cardinal '/XFA'. This function helps me to navigate the complicated object model of the PDF file, which is basically a set of dictionaries embedded inside multiple sets of dictionaries. In the line post-obit the function definition, I am reading in the PDF form and creating a PdfFileReader object. The resolvedObjects method of this grade unravels the PDF object model as a set of Python dictionaries. I and then invoke the findInDict function to extract the elements of the '/XFA' dictionary, which is an array as shown in figure 4 below.

The seventh element of this assortment is the actual XML content that makes upwardly the class. It is an IndirectObject. An IndirectObject is an alias that points to an bodily object. This reference helps to reduce the size of the file when same object appears at multiple places. The getObject() method used in the last line of the code retrieves the actual object. If the object is a text object, using str() part should requite y'all the bodily text. Otherwise, the getData() method needs to be used to return the data from the object. Below is a snapshot of a portion of the XML retrieved in the last line of the code above. You could see some of the dummy address data I entered into the sample grade. You could hands parse out this data from the XML and use information technology for farther assay.
Extracting Data from Acroforms
This one will be relatively easy every bit we have already discussed most of the concepts related with the PDF object model in the sections above. Beneath is a sample income tax form that I will be using equally an instance. I have put some dummy data in information technology.
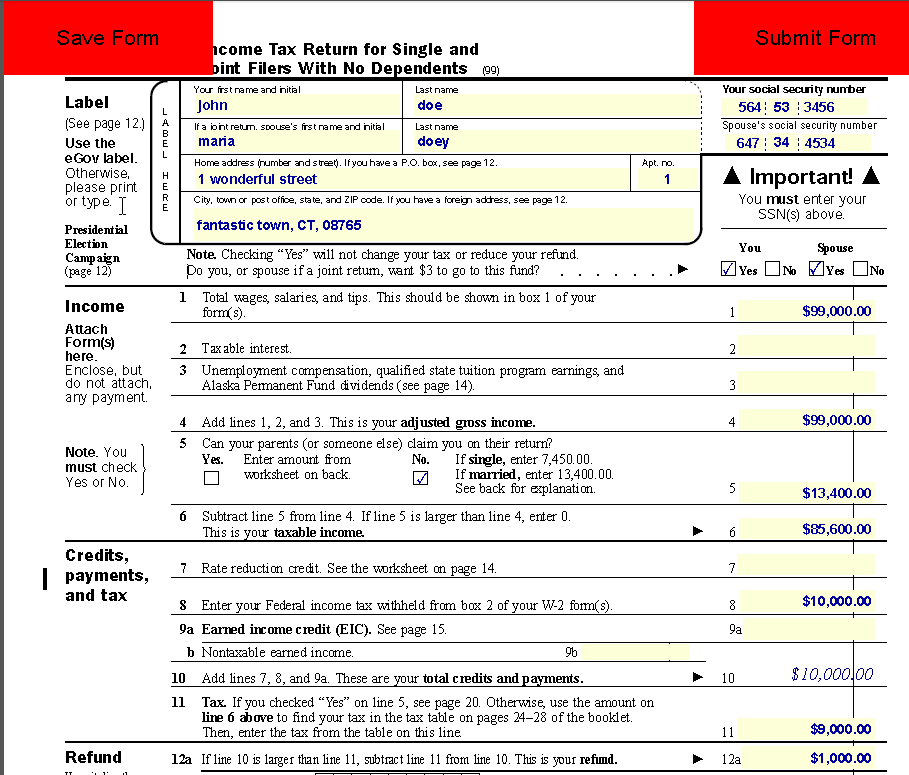
Figure vii below shows the object model of this course.
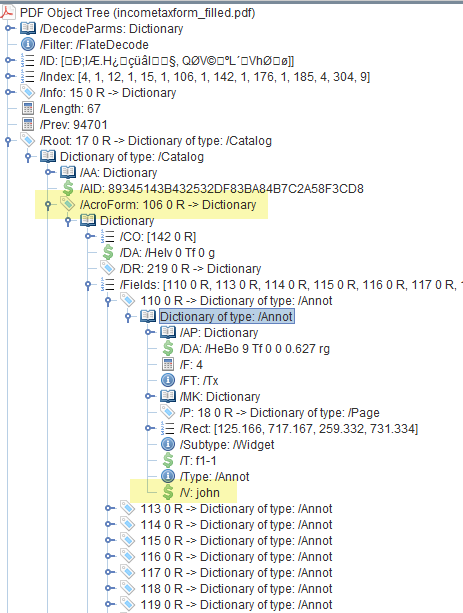
The values of individual grade fields are referenced by the key '/V', which is embedded inside '/Fields', which in turn is embedded inside '/AcroForm'. '/AcroFrom' is a child of the root Catalog lexicon of this PDF file. We could use the approach we used in the instance of XFA grade and use the 'findInDict' function to call back the '/Fields' lexicon and then call up values of the individual fields. Fortunately, PyPDF2 provides a more straight way to do this. The PdfFileReader class provides a getFormTextFields() method that returns a dictionary of all form values. Below is the short code. Figure 8 shows the output. The lexicon object could be hands converted into a list or a Pandas dataframe for farther procecssing.
import PyPDF2 equally pypdf pdfobject=open('incometaxform_filled.pdf','rb') pdf=pypdf.PdfFileReader(pdfobject) pdf.getFormTextFields()

Conclusion
Extracting information from PDF forms is easy once you understand the underlying object model and PyPDF2 is a powerful library that enables yous to access it. Have fun with your data!

Can A Json Script Extract Data From Pdf,
Source: https://towardsdatascience.com/how-to-extract-data-from-pdf-forms-using-python-10b5e5f26f70
Posted by: shiresplesn1976.blogspot.com
0 Response to "Can A Json Script Extract Data From Pdf"
Post a Comment